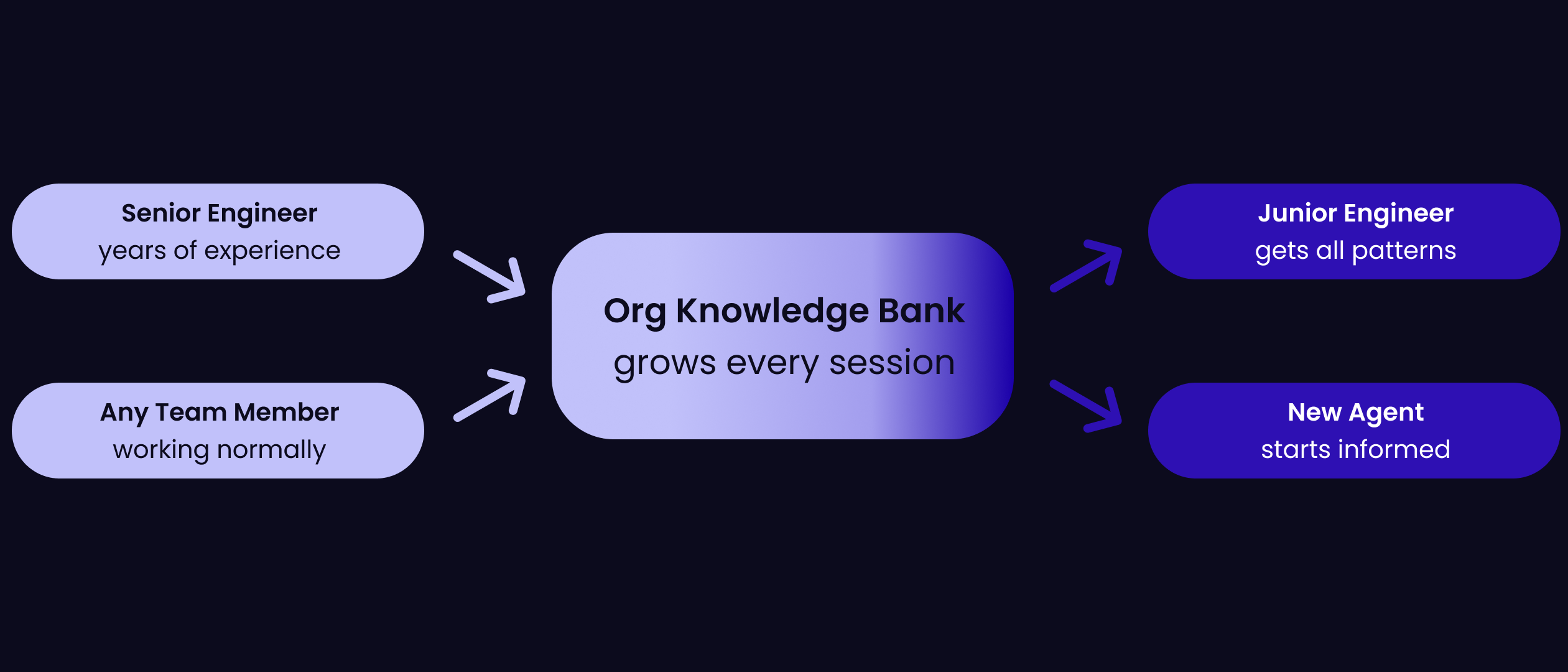
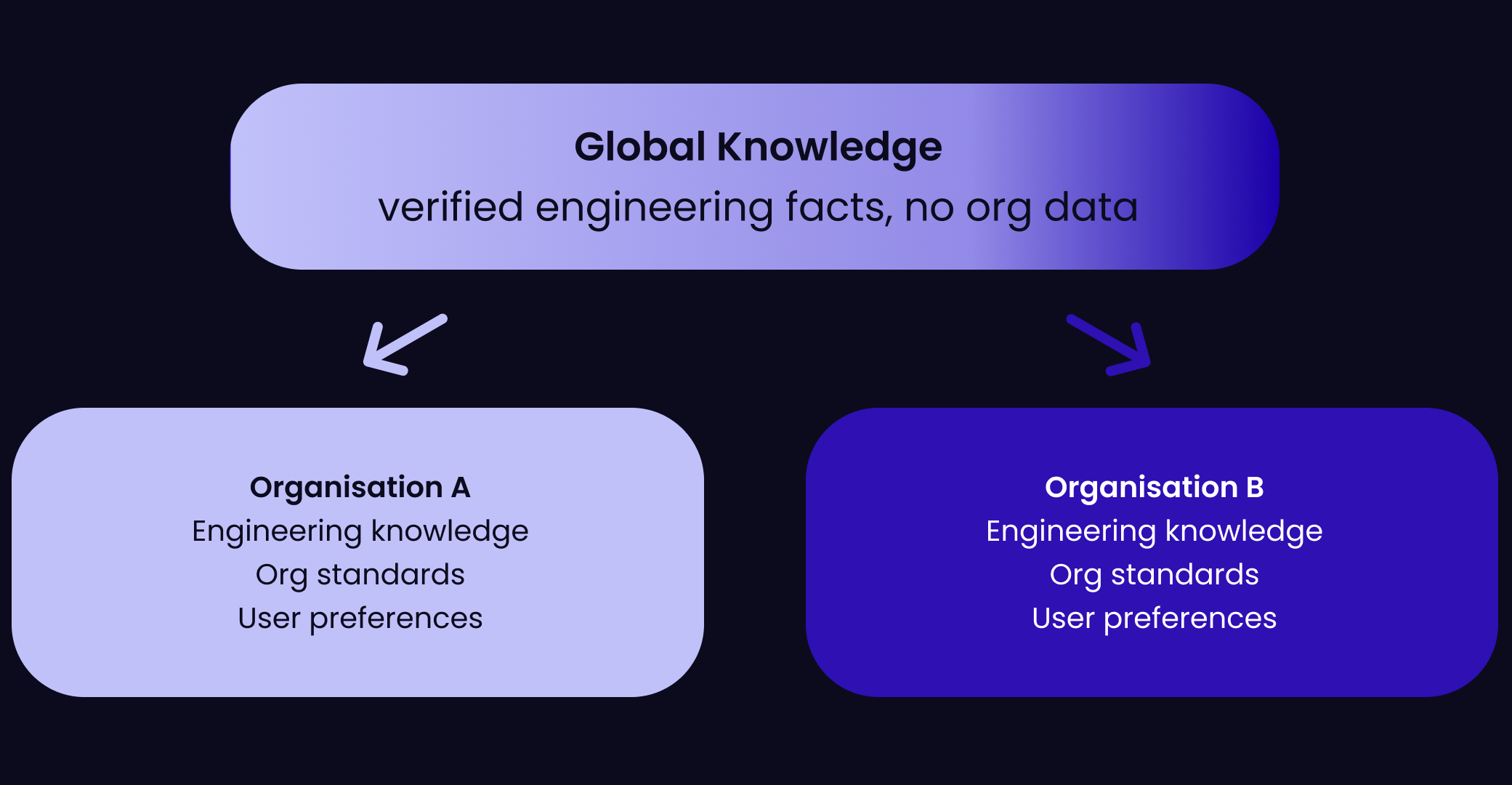
Patterns across memories are more useful than individual memories. This is where the system starts to behave like accumulated expertise.
Every extracted memory gets classified with structured labels that describe what kind of knowledge it is and what it relates to. For failures, we classify the root cause of the problem and how it was resolved. Root causes aren’t symptoms. We classify the underlying issue, not the error message. A failed boolean and a null return from a geometry operation might look different on the surface but both trace back to invalid geometry as the root cause. For workflow knowledge, we classify the operation type and the conditions under which a particular sequence or approach applies. For preferences and standards, we classify scope and context so retrieval surfaces the right knowledge at the right time.
These two axes construct the graph. Memories that share a root cause get linked regardless of which application produced them or how the error was worded. Memories that share a resolution get linked too, because the same class of fix often applies across superficially unrelated problems. The graph edges aren’t hand-authored. They emerge from classification.
Over time, the system synthesizes higher-order observations from clusters of related facts. Individual memories like “apply scale before boolean,” “set origin before boolean,” and “seal any gaps in the geometry before combining shapes, otherwise the software can’t tell what’s inside and what’s outside” get synthesized into a broader principle: boolean operations have strict geometry preconditions, and most failures trace back to skipping a preparation step. An agent retrieving a principle understands the category of problem it’s dealing with and can reason about cases it hasn’t seen before. That’s the difference between an agent that patches errors and one that avoids them.
The graph also handles knowledge going stale. When Blender 4.x changed how object transforms are applied, memories built on the old API behaviour became actively wrong. When a user shifts from one approach to another, older memories can start contradicting newer ones. A memory that read “always use Laplacian smoothing for mesh healing” gets superseded when the user consistently switches to Shrinkwrap instead — the updated memory becomes “user prefers Shrinkwrap for mesh healing; previously used Laplacian but switched due to better preservation of sharp features on thin-walled geometry.” The prior approach isn’t just overwritten. The reasoning behind the change is preserved alongside the new preference.
This matters more than it might seem. An agent that only stores the current preference will apply it blindly. An agent that stores the reasoning can apply judgement: if Shrinkwrap is unavailable in a given context, it understands why the user moved away from Laplacian and can make an informed call rather than silently falling back to a method the user has already decided isn’t good enough. The memory carries the decision, not just the outcome.